|
|
|
Tutorials
Jean-Francois Boulicaut
INSA Lyon
LIRIS CNRS FRE 2672
F-69621 Villeurbanne cedex, France
Jean-Francois.Boulicaut@insa-lyon.fr
Inductive Databases
Ever since the start of the field of data mining, it has been
realized that the data mining process should be supported by database
technology. This idea has been formalized in the concept of inductive
databases introduced by Imielinski and Mannila in a seminal paper that
appeared in CACM 1996. Inductive databases are databases that, in
addition to data, also contain patterns or models extracted from the
data. Within the inductive database framework, a KDD process is modelled
as an interactive process in which users can query both data and
patterns/models to gain insight about the data. To this aim a so-called
inductive query language is used. Very often inductive queries impose
constraints on the patterns/models of interest (e.g. w.r.t. frequency,
syntax, generality, accuracy, significance). The constraint-based
approach to data mining is also closely related to the issue of
declarative bias in machine learning, e.g. to syntactic bias, which
imposes certain (syntactic) constraints on the patterns learned.
Today, a number of specialized inductive query languages have been
proposed and implemented (e.g., MINE RULE by Meo et al., MSQL by
Imielinski et al., DMQL by Han et al.). Most of these query languages
extend SQL and are dedicated to local pattern discovery, e.g.,
association rules. In addition to specific proposals for inductive
query languages, there has also been a large body of research work
concerned with identifying key concepts to be used in inductive
databases. On the one hand, this includes the many types of constraints
and their formal properties (e.g., anti-monotonicity, monotonicity,
succinctness). On the other hand, this concerns the many efficient
algorithms for solving constraint-based queries that have been developed
in both machine learning and data mining (e.g. the levelwise algorithm,
the version space algorithm, condensed representations).
Despite these contributions, we are still far away from a deep
understanding of the issues in inductive databases. In this respect,
one can see an analogy with the state-of-the-art in databases in the
early seventies. In a sense, researchers are looking for the equivalent
of Codd's relational database theory for data mining. This is the
ultimate goal of the cInQ European project (May 2001-May 2004). This
tutorial will, among other things, survey the progress made by the
cInQ consortium in this direction.
Goals
The goals of the tutorial are to introduce the inductive database
framework and the large body of research that is connected to it.
Only very premiminar work has been carried out on an inductive database
approach to global pattern discovery (e.g., constraint-based computation
of clusters or classifiers). This will be briefly considered in the
discussion on perspectives. Local pattern discovery has been much more
studied and has given rise to important concepts. Especially association
rule mining and sequential pattern mining (episodes or sequences,
strings, linear graphs) have been studied extensively the last 3 years.
Therefore, we will illustrate the major concepts of the inductive
database framework on these quite useful data mining tasks.
Our goal is to inform researchers and practionners about the impact
this approach may have for supporting the complex interactive and
iterative data analysis processes.
Overview
- Part 1: Introduction to inductive databases
- What are inductive databases?
- A querying approach to KDD
- Inductive queries and constraint-based mining
- Examples
- Mining association rules from transactionnal data
- Mining sequences in time/space ordered data
- Mining molecular features with Molfea (Kramer et al. 2001)
- Part 2: A simple formalization
- Pattern domains
- Solvers (algorithms)
- Query languages
- Part 3: Examples of specific query languages
- MINE RULE
- MSQL
- DMQL
- MolFea
- What is missing?
- Research challenges
- Part 4: Underlying principles
- What are the primitives?
- Constraint-based mining
- A survey on useful constraints and their properties
- ?-adequate and condensed representations
- A survey of several more or less generic solvers
- Optimizing single queries vs. optimizing a sequence of queries
- Part 5: A research agenda
- Descriptive vs. predictive learning
- Optimisation primitives
- Theoretical and linguistic issues
- Part 6: Conclusion and further readings
Lecturer
Jean Francois Boulicaut is currently associate professor at INSA
Lyon. He got his Ph.D. and his Habilitation from INSA Lyon in 1992 and
2001. His main research interests are: logic programming, (deductive)
databases and knowledge discovery from databases. He has been invited
researcher at the Department of Computer Science in the University of
Helsinki from November 97 until August 98. He created the ``Data Mining
group'' at LISI in October 98. He has served as PC member for several
conferences on database mining and machine learning (PKDD'00, PKDD'01,
ILP'01, PKDD'02, DTDM'02, FCAKDD'02, KDID'02, ILP'03, PKDD'03). In 2002,
he served as the ECAI 2002 tutorial chair and the ECML-PKDD'02 workshop
chair. Currently, he co-chairs the PC of the 2nd International Workshop
on Knowledge Discovery in Inductive Databases KDID'03, co-located with
ECML-PKDD 2003. He is the coordinator of the EU IST project cInQ
"consortium on discovering knowledge with Inductive queries" and has
delivered several tutorials on this topic (PKDD'99, ECML-PKDD'02,
EGC'03).
Alfred Inselberg
Senior Fellow
San Diego SuperComputing Center, San Diego, CA, USA
Computer Science and Applied Mathematics Departments
Tel Aviv University, Tel Aviv, Israel
aiisreal@math.tau.ac.il
Summary
Visualization provides insight through images. For the
visualization of multidimensional (equivalently multivariate)
problems there is need to augment our experience and perception
which are limited by our three-dimensional habitation. Starting with a
literature review the foundations of Parallel Coordinates are
developed, interlaced with applications, enabling the recognition of
multivariate relations from their corresponding visual
patterns.
Description
Intellectual curiosity, and the abundance of important multivariate
problems, motivate the quest for multidimensional visualization
techniques to augment our 3-D perception and experience. Starting from
the early successes of visualization, like Dr. Snow's dot map in 1854
showing the connection of a cholera epidemic to a water well, a short
review of the developments is given. It leads to guidelines for
desirable and attainable properties in such methodologies. The emphasis
being on multidimensional visualization we focus on Parallel
Coordinates which is also a leading methodology for information
visualization. The mathematical foundations for the display and
discovery of multidimensional relations without loss of information
are presented interlaced with a variety of applications. Several
multivariate real datasets (i.e. financial, process control, biomedical,
trading etc) are displayed and explored interactively showing how some
unsuspected complex relations were discovered from visual cues prompted
by the picture. The derivation of algorithms is also motivated by this
visualization and is illustrated with examples from Computer Vision,
Geometric Modeling and Collision Avoidance for Air Traffic Control.
Then geometrical algorithms for Automatic Knowledge Discovery are
derived and applied to real datasets with many (even hundreds) of
variables. These algorithms have low computational complexity, provide
explicit and comprehensible rules, do dimensionality selection by
finding ONLY the parameters containing relevant information, order
these parameters according to some optimality criteria, and provide the
results (including the rules) visually -- see Figure. Finally,
the power to model and display complex nonlinear relations is
illustrated by constructing from data a model of a real country's
economy. Using the model interactively enables the discovery of
plausible economic policies, interrelationships, competition for
resources, impact of constraints downstream, sensitivities and
trade-off analysis. The goal of this course is to provide a working
knowledge of the fundamentals with pointers for further study.
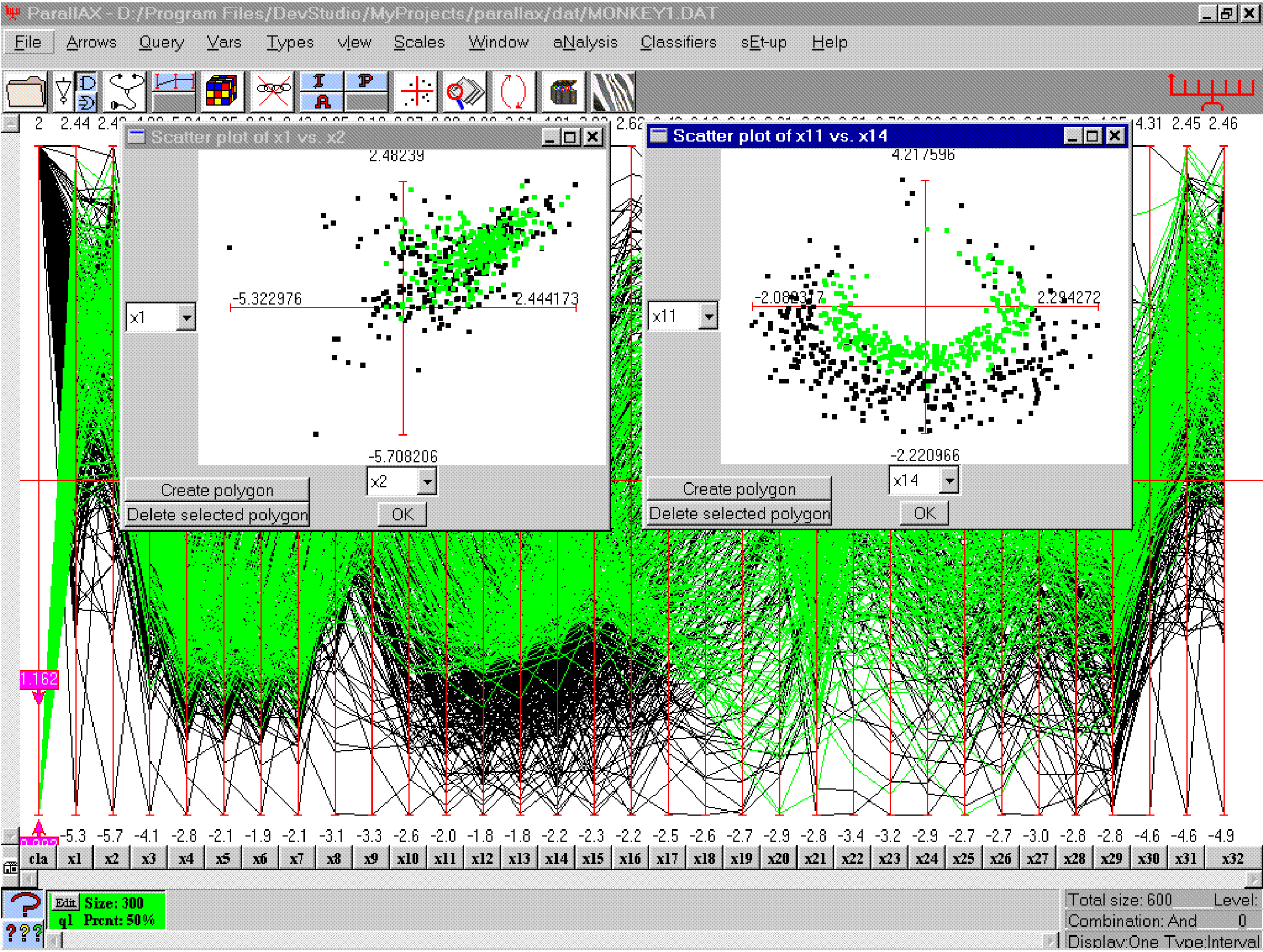
Fig 1: A Monkey neural dataset where the classifier found
the rule to distinguish the behavior of 2 different kinds of neurons
(whose response spikes are colored green and black). Out of the 32
original variables only nine are needed to describe the rule with an
error of about 4%. These variables are ordered according to their
information content. On the left is the scatterplot of the first 2
variables with the order as given, and on the right the best pair of
variables - as found by the classification algorithm - showing the
separation achieved. Note that algorithms based on separation of
clusters by (hyper)planes would not work here as well as those based
on a "nearness" criterion.
Prerequisites
This a self-contained course and no previous background in
visualization is assumed. Mathematical sophistication, knowledge
of geometric algorithms and experience with multivariate problems is
helpful but not necessary.
Overview
- Short Introduction
- The course and its goals
- Background:
Perception, Short History and review of Visualization
methodologies. What are the key and thorny issues in
multidimensional visualization and how can complex RELATIONS
be discovered.
- The basics
- What is a multi-variate relation?
Visualizing approximately linear relations and
interactive demos of Visual Data Mining (Financial,
Process Control and other examples with MANY (even hundreds)
of variables. Audience participation is encouraged.
- Visualizing N-Dimensional Linear and Near-Linear Relations.
- Lines - Representations and their visual patterns
- Minimum Distance between lines
- Application to Collision Avoidance for Air Traffic Control
- animation of resolutions on real examples having several
aircraft with multiple collisions and near
misses, and instances of the One-shot problem.
- Line Topologies for proximity - application to computer
vision and picture reconstruction.
- Planes - and approximated planes (of dimension 2 to N-1),
Hyperplanes and their visual patterns, Data examples from
Process Control, Trading and
Feature discovery in satellite data. A recursive algorithm for
recognizing and displaying higher dimensional objects.
- Transformations
- Curves and Hypersurfaces in N-Dimensions
- Curves starting from Conics
- Smooth Hypersurfaces
- Convexity
- Visual Interior Point Construction Algorithms
- Developable and Ruled Surfaces
- Applications
- Some guidelines for writing good multidimensional visualization
software.
- Automatic Classifier applied to several datasets with lots of
variables, finding rules and errors, displaying the rule
visually as a hypersurface - (Monkey Neural Data 32 parameters,
Identifying enemy vehicles from their noise signature, Finding
water mines from sonar data with 60 parameters), Visual Text
Mining with over 100 parameters, Process Control and Biomedical
Data with over 200 parameters.
- Visual Models of Nonlinear High Dimensional Relations Interior
and Surface Points, Optimization, Discovering interrelations,
sensitivities, effects of constraints, trade-off analysis,
Decision Support. Some fun results and stories ... with
audience participation.
- Research Areas
for students interested in M.Sc. or Ph.D. thesis topics.
Lecturer
Alfred Inselberg (AI): In ancient times AI received a Ph.D. in
Applied Math and Physics from the Univ. of Illinois (Champaign-Urbana)
and then held academic positions in the USA (Univ. of Ill., UCLA, USC)
and abroad. In IBM, where he did research for several years, he became
Senior Technical Corporate Staff Member (a sought after appellation of
dubious value). Subsequently, in 1995 he was elected Senior Fellow in
Visualization at the San Diego SuperComputing Center. He has his own
company Multidimensional Graphs Ltd and is now Professor of Computer
Science & Applied Mathematics at Tel Aviv University. AI invented
(1959) and contributed to the development of Parallel Coordinates, has
several patents, numerous refereed technical papers, professional and
academic awards, and is now writing a book on Multidimensional
Visualization ... and Hi-Tech entertainment.
Tutorial Notes
inselberg.pdf.gz
Attention: Note that this material is
copyrighted and intended for registered attendees of IDA-2003 only.
Nada Lavrac
Intelligent Data Analysis and
Computational Linguistics Research Group
Jozef Stefan Institute
Ljubljana, Slovenia
Nada.Lavrac@ijs.si
Summary
Classical rule learning algorithms are designed to construct
classification and prediction rules. In addition to these "predictive"
induction approaches, developments in "descriptive" induction have
recently gained much attention: clausal discovery, mining of association
rules, subgroup discovery, and other approaches to non-classificatory
induction.
This tutorial will present classical approaches to rule learning,
their upgrade to relational rule learning, and approaches to descriptive
data mining using the methodology of subgroup discovery. It will discuss
the use of heuristics and the rule evaluation criteria, including the
evaluation in the ROC space. It will present a methodology for upgrading
standard rule learning to subgroup discovery, present several case
studies and discuss the lessons learned from these developments.
Overview
- I. Introduction
- Data Mining and Knowledge discovery in databases
- Rule learning and Subgroup discovery
- Motivation for subgroup discovery:
case studies from medicine and marketing
- II. Background: rule learning and subgroup discovery
- Classification rule learning
- Confirmation rule learning
- Association rule learning
- Subgroup discovery
- Heuristics for rule learning and subgroup discovery
- ROC methodology for rule and subgroup evaluation
- III. Subgroup discovery: methodology, case studies
and lessons learned
- The subgroup discovery process
- Shortcomings of classification rule learning for
subgroup discovery
- Weighted covering algorithm, rule subset selection,
probabilistic classification
- Upgrading the CN2 classification rule learner to
subgroup discovery: Algorithm CN2-SD
- Upgrading association rule learning to
subgroup discovery: APRIORI-SD
- Upgrading confirmation rule learning to
subgroup discovery: Algorithms SD and DMS
- Subgroup visualization
- Case studies and lessons learned:
- Case studies in medicine and marketing
- Statistical characterization of subgroups
- Subgroup discovery through supporting factors
- Subgroup interpretation through metaphors
- Actionability of subgroup descriptions
- IV. Relational rule learning and subgroup discovery
- Relational data mining and Inductive logic programming
- Relational rule learning through propositionalization:
Algorithms LINUS, DINUS, SINUS
- Relational subgroup discovery: Algorithm RSD
- Case studies and lessons learned
- V. Summary and conclusions
References
- P. Flach and N. Lavrac. Rule learning.
In M.R. Berthold and D. Hand, eds.
Intelligent Data Analysis: An Introduction, 229-268.
Springer, 2003.
- V. Jovanoski and N. Lavrac. Classification rule learning with
APRIORI-C. In P. Brazdil and A. Jorge (eds.). Progress in
Artificial Intelligence: Knowledge extraction, Multi-agent
systems, Logic programming, and Constraint solving - Proc. of
the 10th Portuguese Conference on Artificial Intelligence,
EPIA 2001, Porto, Portugal, December 17-20 (LNAI 2258), 44-51.
Springer, 2001.
- D. Gamberger and N. Lavrac. Descriptive induction through subgroup
discovery: A case study in a medical domain. In C. Sammut,
A. Hoffmann (eds.) Machine learning: Proc. of the 19th
International Conference (ICML 2002), Sydney, Australia, July 8-12,
2002. 163-170. Morgan Kaufmann, 2002.
- D. Gamberger and N. Lavrac.
Expert-guided subgroup discovery: Methodology and application.
Journal of AI Research, 17:501-527, 2002a.
- B. Kavsek, N. Lavrac and V. Jovanoski: APRIORI-SD: Adapting
association rule learning to subgroup discovery.
Proceedings of the 5th International Symposium on
Intelligent Data Analysis, Springer 2003 (in press).
- N. Lavrac, P. Flach, B. Kavsek and L. Todorovski: Adapting
classification rule induction to subgroup discovery. In Proc. of
the 2002 IEEE International Conference on Data Mining, IEEE Press,
266-273, 2002.
- N. Lavrac, F. Zelezny and P. Flach. RSD: Relational subgroup
discovery through first-order feature construction. In Proc. of
the 12th International Conferences on Inductive Logic Programming
(ILP-2002), 149-165. Sydney, Australia, July 9-12, 2002.
Springer, 2003.
Lecturer
Nada Lavrac is head of the Intelligent Data Analysis and
Computational Linguistics research group at the Department of
Intelligent Systems, Jozef Stefan Institute, Ljubljana, Slovenia.
Her main research interests are in machine learning, in particular
Relational Data Mining and Applications of Machine Learning in
Medicine. She was scientific coordinator of ILPNET (1992-1995), and
cocoordinator of the Sol-Eu-Net project Data Mining and Decision
Support for Business Competitiveness: A European Virtual Enterprise
(2000-2003). She is co-author of Inductive Logic Programming:
Techniques and Applications (Ellis Horwood, 1994), and co-editor of
Intelligent Data Analysis in Medicine and Pharmacology (Kluwer, 1997),
Relational Data Mining (Springer, 2001) and Data Mining and Decision
Support: Integration and Collaboration (Kluwer 2003, in press). She
has been program co-chair of ECML'95, ILP'97 and ECML/PKDD-2003, and
editorial board member of Machine Learning Journal, Artificial
Intelligence in Medicine, New Generation Computing, Applied Artificial
Intelligence, and AI Communications.
Nada Lavrac has taught graduate courses at the universities of
Klagenfurt, Stockholm, Linkoping, Sao Paulo, Aarhus, Bristol and
Torino. She has given tutorials at SCAI'93, GULP'96, IJCAI'97, GP'98,
ECAI'98, AIME'99 and ECAI'02.
|
|